Overview

Abstract.Robotic manipulation policies have made rapid progress in recent years, yet most existing approaches give limited consideration to memory capabilities. Consequently, they struggle to solve tasks that require reasoning over historical observations and maintaining task-relevant information over time, which are common requirements in real-world manipulation scenarios. Although several memory-aware policies have been proposed, systematic evaluation of memory-dependent manipulation remains underexplored, and the relationship between architectural design choices and memory performance is still not well understood. To address this gap, we introduce RMBench, a simulation benchmark comprising 9 manipulation tasks that span multiple levels of memory complexity, enabling systematic evaluation of policy memory capabilities. We further propose Mem-0, a modular manipulation policy with explicit memory components designed to support controlled ablation studies. Through extensive simulation and real-world experiments, we identify memory-related limitations in existing policies and provide empirical insights into how architectural design choices influence memory performance.
Mem-0 Policy
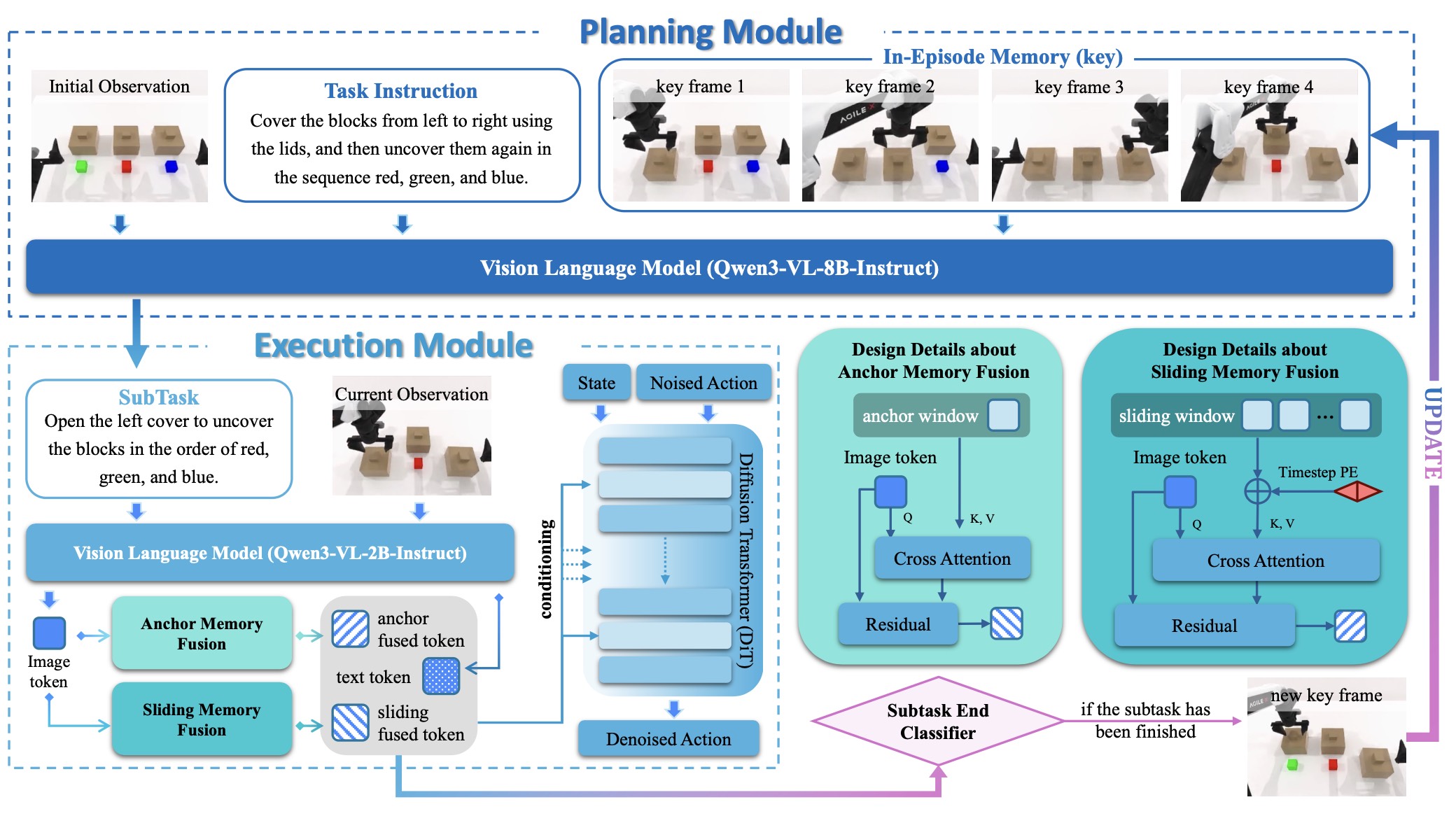
Mem-0 Pipeline. Mem-0 comprises a Planning Module and an Execution Module linked by a Subtask End Classifier. The Planning Module generates high-level subtasks from task instructions, observations, and key-frame memory, while the Execution Module produces low-level actions using the current observation, the subtask, and fused anchor and sliding memories in a diffusion-based policy. Upon subtask completion, a key frame is stored to enable iterative planning and execution until task completion.
Benchmark and Study
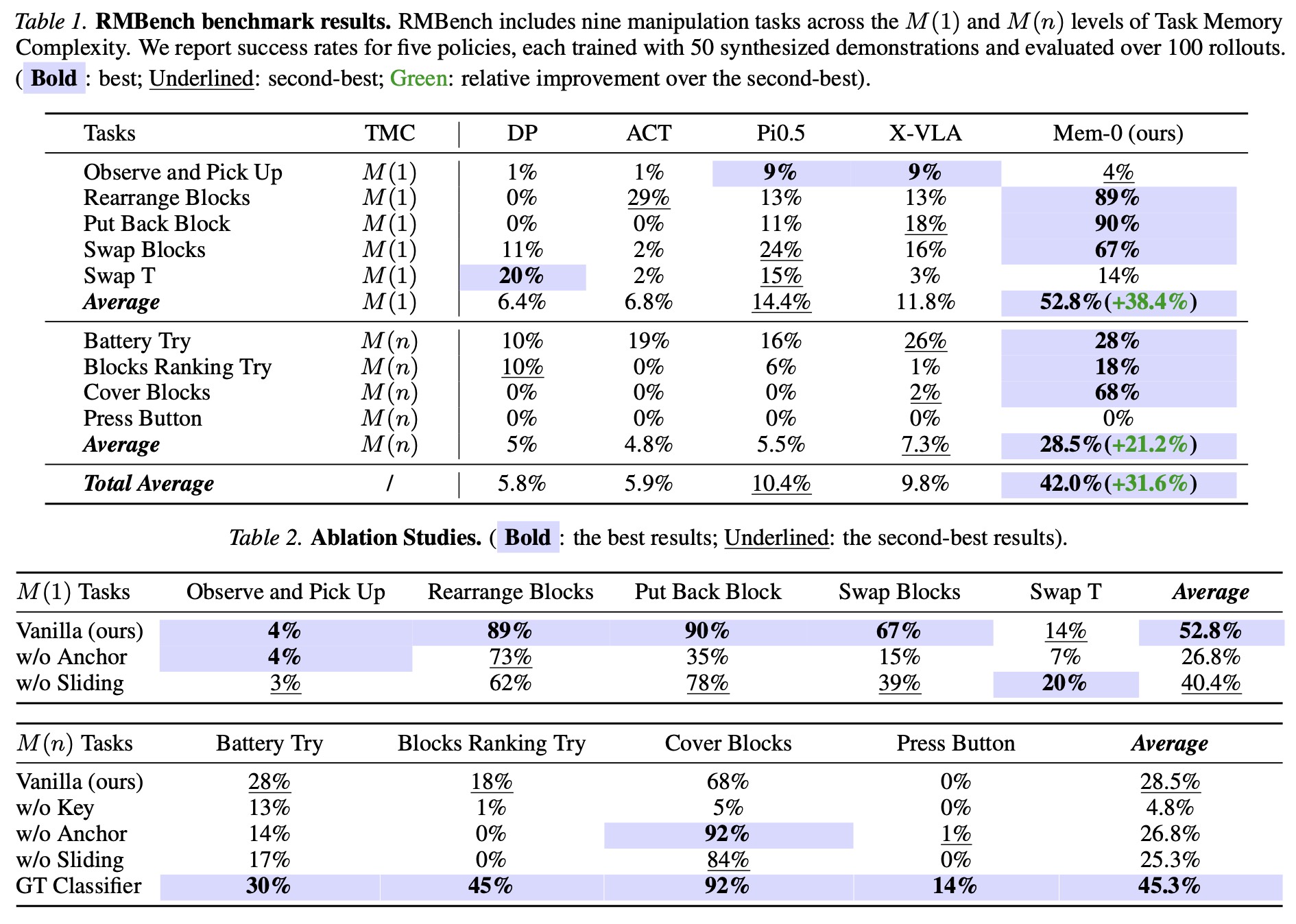
Error Analysis

BibTeX
@misc{chen2026rmbenchmemorydependentroboticmanipulation,
title={RMBench: Memory-Dependent Robotic Manipulation Benchmark with Insights into Policy Design},
author={Tianxing Chen and Yuran Wang and Mingleyang Li and Yan Qin and Hao Shi and Zixuan Li and Yifan Hu and Yingsheng Zhang and Kaixuan Wang and Yue Chen and Hongcheng Wang and Renjing Xu and Ruihai Wu and Yao Mu and Yaodong Yang and Hao Dong and Ping Luo},
year={2026},
eprint={2603.01229},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2603.01229},
} If you have any questions, please contact us at chentianxing2002@gmail.com.